[實作資源] 本文所述之 llm-wiki 完整目錄結構、AGENTS.md 操作規範與相關模板已封裝為壓縮檔。讀者可逕行下載,作為建置環境之參考:https://reurl.cc/M2zlAW
前言
在上一篇文章〈Karpathy LLM Wiki 知識系統實踐:解析核心理念〉中,我整理了 Karpathy 所提出的 LLM Wiki 方法論,其核心並不在於使用某個特定工具,而是建立一套可以持續演化的知識處理流程:
- 原始資料放在
raw/ - LLM 將資料整理為
wiki/ - 透過
AGENTS.md或CLAUDE.md定義操作規範 - 每次新增資料時,不只是產生摘要,而是整合進既有知識結構
這篇接續上一篇,聚焦在「基礎建置」:如何用最少工具,先建立一個可運作的 Karpathy LLM Wiki。
這裡的目標不是一次就打造完整系統,也不是導入複雜 RAG、向量資料庫或自動化 pipeline,而是先建立一個最小可行流程(Minimum Viable Workflow):
能收集資料、能讓 LLM ingest、能產出 wiki、能持續查詢與維護。
準備工具
基礎設置只需要三類工具。
1. Obsidian
Obsidian 是本地 Markdown 筆記工具,在這套方法中扮演 Wiki 的載體。
Karpathy 對它有一個很直覺的比喻:
- Obsidian 是 IDE
- LLM 是 programmer
- Wiki 是 codebase
也就是說,我們不是把 Obsidian 當成一般筆記軟體,而是把整個 Vault 視為一個由 LLM 維護的知識工程專案。
Obsidian 的好處在於:
- 所有內容都是本地 Markdown 檔案
- 支援
[[wikilinks]]雙向鍊結樣式 - 可以用 Graph View 檢視知識圖譜
- 不需要先導入資料庫或雲端服務
2. LLM Agent
第二個工具是能操作本地檔案的 LLM Agent,例如:
- OpenAI Codex
- Claude Code
- Gemini
- 使用如 Ollama 建置本地的 LLM
- 其他可讀寫本地 Markdown 檔案的 agent
重點不是模型品牌,而是它必須能做到幾件事:
- 讀取
raw/裡的來源 - 在
wiki/建立與更新 Markdown - 維護
index.md與log.md - 依照規格檔執行 ingest、query、lint
如果使用 Codex,該行為規範檔名命名為 AGENTS.md;而如果使用 Claude Code,則命名為 CLAUDE.md。
兩者在概念上扮演同一個角色:告訴 LLM 這個知識庫應如何被維護。
3. Obsidian Web Clipper
第三個工具是 Obsidian Web Clipper。
它不是必要條件,但很實用。因為多數研究素材來自網頁文章、Youtube、技術文件、Blog、教學文章等。Web Clipper 可以直接把網頁轉成 Markdown,保存到 Obsidian Vault(可以指定任一 Vault) 中。
在這套流程裡,建議將 Web Clipper 的輸出位置設定為:/raw
如果文章中有圖片,也建議讓附件下載到:raw/assets/
這樣原始資料與附件就會一起保存在本地,避免日後網頁圖片失效,LLM 也可以在需要時檢視圖片內容。
創建 LLM Wiki Vaullt 目錄結構
安裝 Obsidian 後,先建立一個新的 Vault,本例命名為:llm-wiki-demo。
啟動 Obsidian 並開啟該 Vault,接著需要執行對應的 LLM Agents。Obsidian 可透過安裝 obsidian-terminal 插件,在應用程式內直接呼叫 Agent CLI。然而,在 Windows 11 上的使用體驗並不理想,因此本例改採在 Vault 目錄下另開 PowerShell 執行 Codex CLI,並將兩個應用程式並排顯示於同一螢幕,以便同步檢視與操作。
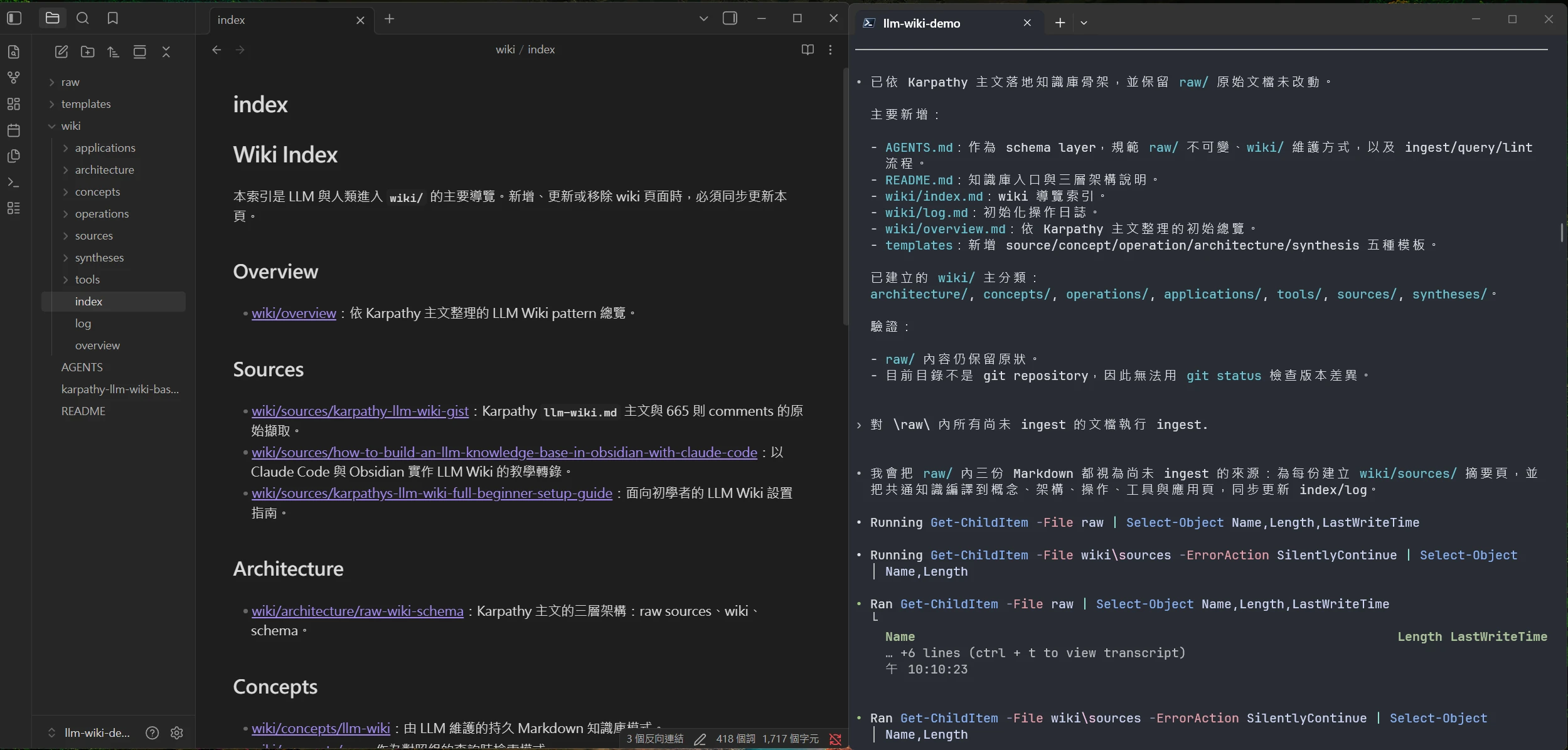
接著無需手動逐一建立目錄與檔案結構。我的作法是只先建立 \raw 目錄,並透過 Codex CLI 將 Karpathy 發表於 Gist 的 LLM Wiki 下載至該目錄。同時,也要求 Agent 一併擷取所有留言討論,整理並儲存為單一 Markdown 文件。
然後我在 Agent CLI 聊天框內輸入以下訊息:
根據
raw/karpathy-llm-wiki-gist.md的主文內容(僅採用其三層目錄架構,不納入留言討論中的建議),建立本llm-wiki-demo的知識庫目錄結構。既有raw/內的原始文檔則維持不變。
建議啟用 /plan 模式,讓 Agent 在實際建立目錄前,先確認所採用的結構符合主文所建議的設計。以下為最小必要的目錄結構:
llm-wiki-demo/ # Obsidian vault 根目錄
├─ AGENTS.md # LLM Wiki schema 與操作規範
├─ raw/ # 原始來源層,作為 source of truth
├─ templates/ # wiki 頁面與紀錄模板
└─ wiki/ # 由 LLM 維護的知識頁主體最後,Agent 會依據 Karpathy 的 LLM Wiki 主文建立目錄結構,並生成必要的規範檔(AGENTS.md 或 CLAUDE.md)、索引(index)與日誌(log)等完整模板,最終呈現在 Obsidian 的檔案目錄窗格中。
透過 Web Clipper 設定與擷取網頁內容
Obsidian 官方推出的 Web Clipper 插件功能相當強大!它的主要功能特徵有:
- 一鍵擷取網頁內容並儲存為 Obsidian 筆記;支援擷取 YouTube 影片並將逐字稿一併保存
- 支援頁面文字高亮(Highlight)並一併保存
- 可選擇擷取完整頁面或特定區塊(如文章主體)
- 自動轉換為 Markdown,保留基本結構與格式
- 支援自訂模板與指定儲存位置(Vault/資料夾)
安裝 Obsidian Web Clipper 後,建議設定:
- Vault:選擇你的 LLM Wiki Vault
- Save location:
raw/ - Attachment folder:
raw/assets/
這樣每次剪藏網頁時,就會直接進入 raw source 層。
一個基本流程會是:
- 在瀏覽器看到值得研究的文章或影片
- 用 Obsidian Web Clipper 存到
raw/ - 若文章有圖片,下載到
raw/assets/ - 回到 LLM Agent,要求 ingest 該來源
這裡要注意一點:不要把 Web Clipper 剪下來的文章直接當成整理後的知識。
它只是 raw source。
真正的整理工作,應由 LLM 在 wiki/ 中完成。
第一次 Ingest
當目錄與規格建立完成後,就可以進行第一次 ingest(擷取)。
當 \raw 目錄內有多筆尚未被 ingest 處理過的原始文檔,就可以對 Agent 下達如下的指令:
請 ingest raw/ 內所有尚未 ingest 的來源。
理想情況下,LLM 不應只產生一篇摘要,而是會建立多個頁面,例如:
wiki/
├─ sources/
│ └─ karpathy-llm-wiki-gist.md
├─ concepts/
│ ├─ llm-wiki.md
│ ├─ rag.md
│ ├─ persistent-wiki.md
│ ├─ raw-sources.md
│ ├─ wiki-layer.md
│ └─ schema-layer.md
├─ operations/
│ ├─ ingest.md
│ ├─ query.md
│ └─ lint.md
├─ architecture/
│ └─ raw-wiki-schema.md
├─ index.md
└─ log.md這才是 LLM Wiki 的精神:把來源整合進一個可持續維護的知識結構。
查詢與回寫
完成第一次 ingest 後,就可以開始用 wiki 提問。
例如:
請根據 wiki,說明 LLM Wiki 與傳統 RAG 的差異。
或:
請比較 raw/wiki/schema 三層架構各自的責任。
在回答時,LLM 應該先讀:
wiki/index.md
再依照索引讀相關頁面。
如果回答產生了有長期價值的整理,例如:
- 一份比較表
- 一個設計取捨分析
- 一個跨來源綜合結論
- 一份未來改進建議
就應該要求 LLM 將它回寫到:
wiki/syntheses/
這就是 query file-back。
它能讓每一次查詢不只是得到答案,也能讓知識庫本身變得更完整。
知識圖譜
當 LLM Agent 完成多次 Ingest 並在 wiki/ 目錄下生成多個具備雙向連結([[wikilinks]])的 Markdown 文件後,知識庫便從平面的文檔堆疊轉化為具備拓樸結構的知識網路。
透過 Obsidian 的知識圖譜(Graph View),我們可以對系統進行以下實務觀察:
- 語義網路的實體化:圖譜中的節點代表概念(Concepts)或來源(Sources),連線則是 LLM 根據
AGENTS.md規範所識別出的邏輯關聯。這將原本隱含在內文中的知識脈絡,轉化為直觀的架構圖。 - 知識成熟度評估:密集的節點集群(Clusters)代表該領域已有足夠的交叉參照與資訊深度;相對地,孤立節點(Orphan Nodes)則揭示了知識庫中的斷層,作為後續執行
lint或補充raw資料的標靶。 - 驗證 Codebase 結構:誠如 Karpathy 所述,Wiki 是 Codebase,而圖譜即是該 Codebase 的架構藍圖。透過視覺化,維護者能確認
index.md是否正確發揮樞紐節點(Hub)的作用,確保 LLM 在執行查詢時能循序存取相關路徑。
這種展現方式不僅是為了美觀,更是確保知識系統在演化過程中,始終保持結構化的完整性與可導航性。

定期 Lint Wiki
當 wiki 開始累積頁面後,需要定期檢查健康狀態。
可以直接要求:
請 lint 這個 wiki,檢查是否有矛盾、過期資訊、孤立頁、缺少 backlinks、重要概念缺頁,並提出修正建議。
Lint 應檢查:
- 是否有頁面互相矛盾
- 是否有舊結論被新來源推翻
- 是否有孤立頁
- 是否有概念被多次提到但沒有獨立頁
index.md是否漏列頁面log.md是否記錄最近操作
這個步驟很重要。
因為知識庫真正困難的不是新增資料,而是長期維護。
知識庫的持續維護與整理,對於知識工作者是很煩心的工作,而這反而是 LLM 最為專長所在。
基礎設置完成後的目錄樣貌
一個完成基礎 ingest 後的 Vault,大致會像這樣:
llm-wiki-demo/ # Obsidian Vault 根目錄
├─ raw/ # 原始來源層;來源真相,不應由 LLM 修改
│ └─ assets/ # raw 來源引用的圖片、附件與本地資產
├─ templates/ # Wiki 頁面模板;供後續 ingest/query/lint 建頁使用
│ ├─ architecture.md # 架構頁模板
│ ├─ concept.md # 概念頁模板
│ ├─ operation.md # 操作流程頁模板
│ ├─ source.md # 來源摘要頁模板
│ └─ synthesis.md # 綜合分析頁模板
├─ wiki/ # LLM 生成與維護的知識庫主體
│ ├─ applications/ # 應用場景頁;如 personal、research、business/team
│ ├─ architecture/ # 架構與資料流頁;如 raw → wiki → schema
│ ├─ concepts/ # 核心概念頁;如 RAG、persistent wiki、schema
│ ├─ operations/ # 操作流程頁;如 ingest、query、lint
│ ├─ sources/ # raw 來源的摘要與 metadata 頁
│ ├─ syntheses/ # 跨來源綜合分析與 query file-back 頁
│ ├─ tools/ # 工具與整合方式;如 Obsidian、qmd、MCP
│ ├─ index.md # Wiki 內容索引;回答問題前優先讀取
│ ├─ log.md # 時序操作日誌;記錄 ingest/query/lint/update
│ └─ overview.md # 知識庫總覽;目前對 LLM Wiki pattern 的整體理解
├─ AGENTS.md # Schema layer;定義 Codex/LLM 如何維護此 Vault
├─ README.md # README文件,介紹三層架構與基本工作流這個結構已經足以支撐基礎使用:
- 新資料進
raw/ - LLM 維護
wiki/ AGENTS.md定義行為index.md導覽內容log.md追蹤演化
此時還不需要導入向量資料庫、MCP 或複雜搜尋工具。
先讓流程跑起來,比一開始就把架構做大更重要。
一些實務建議
1. 一次 ingest 一份來源
初期建議一次只 ingest 一份來源。
這樣比較容易檢查 LLM 的整理結果,也比較容易調整 AGENTS.md 的規則。
等流程穩定後,再考慮批次 ingest。
2. 不要讓 LLM 修改 raw
這點要反覆強調。
raw/ 是原始證據,不是工作區。
如果 LLM 整理錯了,可以修 wiki;但如果 raw 被改掉,就失去追溯依據。
3. index.md 要保持簡潔
index.md 不是全文目錄,也不是所有內容的複製。
它應該是一份導覽:
- 頁面名稱
- 一句話摘要
- 分類
- 必要 metadata
它的用途是讓人與 LLM 都能快速找到入口。
4. log.md 要持續追加
log.md 不需要寫得很長,但一定要記錄操作。
最重要的是:
- 何時 ingest
- ingest 了什麼
- 建立或更新了哪些頁
- 是否有 query 被回寫
- 是否做過 lint
5. 先用 Markdown,再談工具升級
當 wiki 還在早期階段時,不需要急著加搜尋引擎、資料庫或自動化。
等到你真的遇到問題,例如:
- 頁面太多,index 不夠用
- 查詢需要全文搜尋
- 多人或多 agent 同時維護
- 需要更嚴格的 metadata 查詢
再考慮導入 qmd、MCP、Obsidian Bases、Dataview 或 SQLite 等工具。
結語
Karpathy LLM Wiki 的基礎設置其實不複雜。
真正重要的是建立正確分工:
raw/保存原始資料wiki/保存整理後的知識AGENTS.md或CLAUDE.md定義 LLM 的操作規範index.md幫助定位log.md保存演化紀錄
這套方法的價值,不在於一次產生漂亮的筆記,而在於讓知識可以持續累積與維護。
當新資料加入時,LLM 不是重新開始,而是把新資料整合進既有結構。
當你提出問題時,答案也不只是聊天回覆,而可以回寫成新的知識頁。
這就是 LLM Wiki 和傳統文件整理或一次性 RAG 最大的差別。
下一步,等基礎流程穩定後,就可以進一步討論如何導入 skill、搜尋工具與自動化流程,讓這套知識系統更適合長期維運。